What Makes It Efficient and Cost-Effective
DeepSeek-R11 was trained for approximately $5.58 million, a fraction of the estimated $100 million to $1 billion for OpenAI’s o1 model. It achieves a 45x boost in training efficiency by leveraging 8-bit precision instead of 32-bit floating point, drastically reducing memory consumption. Sparse attention mechanisms, such as Multi-Head Latent Attention, compress key-value indices—typically responsible for high VRAM usage—by 93%. Multi-token prediction doubles inference speed, while the Mixture of Experts (MoE) framework decomposes a large model into smaller sub-models that run efficiently on consumer-grade GPUs. Instead of relying on Proximal Policy Optimization (PPO)2, DeepSeek-R1 introduces Group Relative Policy Optimization (GRPO)3, eliminating the need for a separate critic model.
Training Pipeline
Phase 1: DeepSeek-R1-Zero (Pure RL)
DeepSeek R1 employs a novel Reinforcement Learning framework that relies on GRPO, a cost-efficient algorithm that eliminates the need for a critic model by estimating baselines through comparisons of past policy outputs. The reward design centers on evaluating correctness—verifying math answers via formatting or running code test cases—and enforcing structured output with tags to enhance readability. A carefully crafted training template further encourages the model to reason through problems before generating answers, reducing content biases.
One of the key breakthroughs in this phase is the “Aha Moment”, during which the model begins to exhibit more in-depth reasoning patterns. As shown in below figures, the average response length of DeepSeek-R1-Zero steadily grows throughout RL training, suggesting that additional reasoning time correlates with improved problem-solving. In the example question, DeepSeek-R1-Zero demonstrates how it systematically tackles complex expressions by verifying solutions step by step, thereby showcasing its evolving reasoning capabilities.
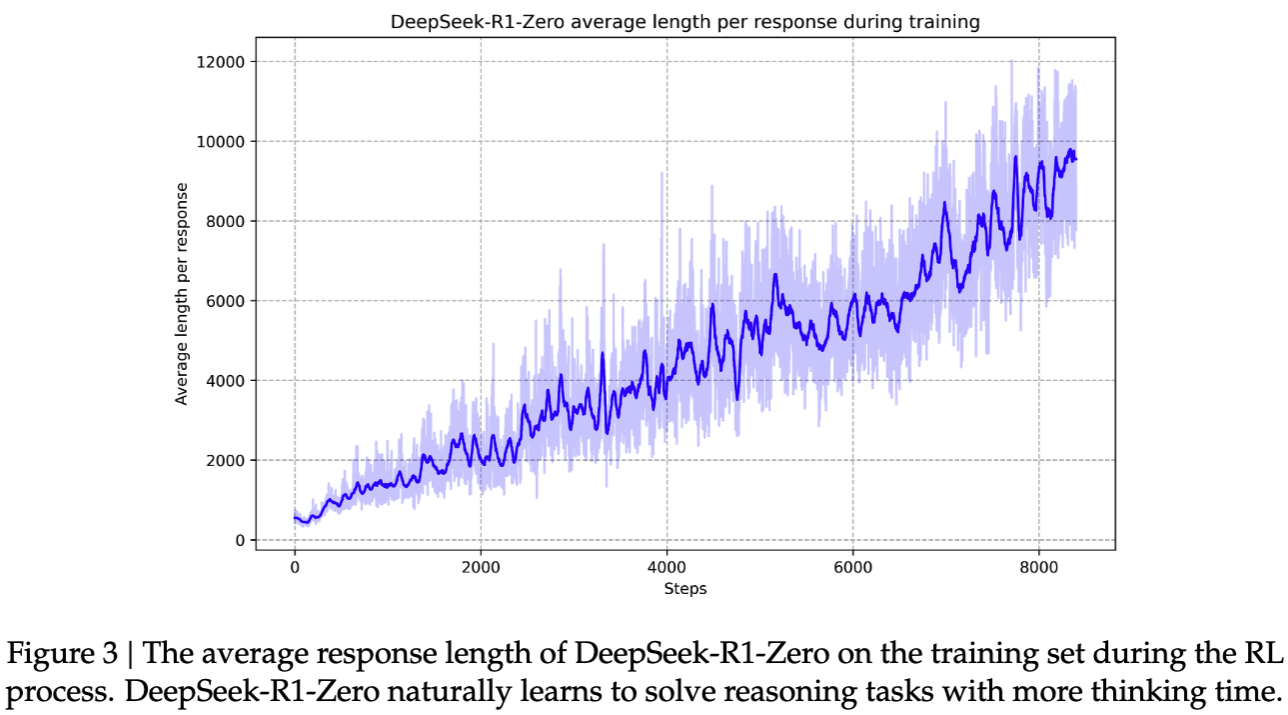

DeepSeek-R1-Zero achieved a 71% pass@1 on AIME 2024, a figure that climbed to 86.7% when majority voting was applied—on par with OpenAI’s o1-0912. Despite this strong performance, the model exhibited several notable limitations, including reduced readability, instances of language mixing, and repetitive outputs.
Phase 2: DeepSeek-R1 (Cold-Start Data + Multi-Stage Training)
To address the shortcomings observed in R1-Zero, DeepSeek introduced a comprehensive four-stage pipeline. In the Cold-Start Fine-Tuning stage, the model was trained on thousands of high-quality, human-curated CoT examples to bolster initial stability and readability; these examples were sourced from few-shot prompts, refined R1-Zero outputs, and manual annotations. This was followed by a Reasoning-Oriented RL phase, where GRPO was augmented with additional language consistency rewards to reduce mixed-language outputs, slightly sacrificing performance in favor of alignment with human preferences. The third stage employed Rejection Sampling and Supervised Fine-Tuning (SFT), during which 800k samples were generated and low-quality outputs were filtered out. These were then combined with DeepSeek-V3’s general-task data—spanning writing and Q&A—to broaden the model’s versatility. The final Full-Scenario RL stage aligned the model with human preferences by using rule-based rewards for reasoning tasks and neural reward models for more general tasks.
Phase 3: Distillation for Smaller Models
In the final phase, DeepSeek distilled R1’s reasoning capabilities into smaller models ranging from 1.5B to 70B parameters via supervised fine-tuning on its curated set of 800k samples. Notably, the DeepSeek-R1-Distill-Qwen-32B model achieved a 72.6% pass@1 on AIME 2024, outperforming OpenAI-o1-mini. The distillation process proved more effective than directly applying RL to small models; for example, a Qwen-7B model scored 55.5% pass@1 compared to 44% for an RL-trained Qwen-32B. Distillation not only transferred advanced reasoning strategies such as self-verification and reflection but also reduced training costs by approximately 90% by eliminating the need for a dedicated RL infrastructure. Even the 1.5B model demonstrated superior performance on specific math benchmarks, underscoring the efficiency of this knowledge transfer.
Innovations and Challenges
DeepSeek-R1 validates the potential of pure reinforcement learning for reasoning without the need for supervised fine-tuning, while also demonstrating effective distillation techniques that enable smaller models to inherit advanced reasoning capabilities from larger counterparts. However, challenges remain, including issues with language mixing, prompt sensitivity, and limited general capabilities such as structured JSON output. Future work will focus on extending RL to software engineering tasks, optimizing multilingual support, and refining prompt robustness.
Mark Chen from OpenAI4 remarked,
Their research paper demonstrates that they’ve independently found some of the core ideas that we did on our way to o1.
- We have two paradigms (pre-training and reasoning) to optimize model capability over two axes instead of one. Both axes can be scaled aggressively.
- Advances in distillation research reveal that lowering serving costs (e.g., through higher latency) does not inherently improve capabilities.
What does Pure RL mean?
Simplicity is the ultimate sophistication. — Leonardo da Vinci
Pure RL differs from RLHF; from an RL perspective, large language models have evolved from autoregressive pretraining (as in GPT-3) to autoregressive pretraining combined with RLHF (as in ChatGPT), and now to autoregressive pretraining with pure RL (as exemplified by O1 and R1). The rationale behind pure RL is that models should be capable of independent search and reasoning, without relying on artificially imposed inductive biases or rigidly structured thought processes. This approach emphasizes the use of exact rewards rather than reward models, as the latter are inherently prone to reward hacking—a phenomenon where an imperfect RL environment makes it challenging to define an accurate reward function56. As Goodhart’s Law warns, “When a measure becomes a target, it ceases to be a good measure.”
Why pure RL suddenly work?
Kevin Patrick Murphy said7
I read the R1 zero paper and the method is very simple, just a tweak to PPO to fine tune deepseek v3 base using a verifiable sparse binary reward. The fact that they got it to work even though others failed is likely due to better data and/or their very efficient implementation
Efficient Quant Fund
DeepSeek’s success in RL may partly be due to its exceptionally efficient implementation, which could be influenced by its roots in quantitative finance. Although often described as a side project, DeepSeek operates much like a well-funded independent lab—a fact that resonates with Mark Chen’s background in quant finance (perhaps it’s not a bad idea to do quant before AI).
The Role of Data
Another contributing factor may be the incorporation of OpenAI O1 outputs into the training data. The “Distributed Chain of Thought” Hypothesis, as posed by Theia8, suggests that pretraining datasets have inadvertently become a massive, distributed CoT annotation program. Large language model outputs that include explicit reasoning steps and correctness markers have leaked into these datasets, enriching the training process for RL models. This contamination enables GRPO-trained models to generalize from strictly verifiable domains like math to more ambiguous tasks such as writing. As R1 continues to generate structured CoT outputs, this self-reinforcing cycle will likely enhance the reasoning abilities of future models.
Can We Reproduce Aha Moments?
Berkeley Team
The Berkeley team replicated DeepSeek-R1-Zero within the CountDown game context. Their findings confirmed that the base model’s quality is paramount, as instruction-tuned models converge faster yet perform similarly to base models. Their experiments also confirmed that no SFT is required to validate a pure RL approach, and the choice of RL algorithm—whether PPO, GRPO, or PRIME—had minimal impact, as all produced robust CoT reasoning.


HKUST Team
The HKUST team reproduced both DeepSeek-R1-Zero and DeepSeek-R1 using a 7B model with just 8K samples, outperforming Qwen2.5-Math-7B-Instruct and achieving results comparable to PRIME and rStar-MATH, despite using 50× less data. Their method involved applying RL after a long CoT SFT phase, without any SFT or reward models. They observed that accuracy steadily improved across benchmarks during RL training, with output lengths initially decreasing—indicating a pruning of ineffective reasoning patterns—before later increasing as self-reflection and extended CoT reasoning emerged. A similar pattern was observed by Berkeley’s team, where smaller models first shortened outputs for proper formatting and then expanded their CoT reasoning to improve performance.

Can We Train a “True” DeepSeek-R1-Zero from Scratch?
An open question remains as to whether DeepSeek-R1-Zero can be trained from random weights—similar to AlphaZero—or if leveraging a pretrained LLM is essential. Hugging Face is currently exploring a full reproduction in Open-R1.
Mixed-language Internal Thinking
Why Does It Happen?
DeepSeek-V3, the base model, was likely trained on multilingual corpora, including Chinese and English, enhancing versatility but also leading to unintended language blending. During RL training, the reward function prioritized correctness and formatting but did not penalize language mixing, allowing multilingual responses to persist. Rejection sampling further reinforced this issue by filtering for correctness and readability rather than strict language consistency, permitting occasional Chinese terms in English responses to pass. Additionally, the tokenizer treats Chinese characters and English words as distinct tokens without recognizing language boundaries. This leads to contextual language switching in long reasoning chains, where the model may process intermediate steps in Chinese and final answers in English, likely influenced by prior exposure to code-switched examples.
Impact on Performance
DeepSeek-R1 achieved a 79.8% pass@1 on AIME 2024, surpassing R1-Zero’s 71.0%. However, readability-focused rewards resulted in a ~2% drop in some metrics compared to a readability-agnostic version. Similar declines appeared in tasks requiring unconventional reasoning, where strict formatting constraints limited creative problem-solving. While the language consistency reward reduced mixed-language outputs, it occasionally filtered out valid reasoning pathways, slightly lowering accuracy.
Bug or Feature?
Tokenization in LLMs functions as a “meta-language,” treating multilingual and symbolic tokens as abstract representations. This abstraction may enable novel reasoning pathways that blend languages or symbols, aligning with research on evolutionary search strategies and mind evolution910. Additionally, implicit CoT reasoning—where models process logic internally rather than generating explicit intermediate steps—improves efficiency by reducing reliance on word-by-word reasoning11. As RL-trained models begin to exhibit strategies akin to AlphaGo’s Move 3712, AI may develop its own internal reasoning structures, potentially surpassing human-designed logic frameworks.
The Fundamental Difference: RL vs. Supervised Learning
“Every single stunning example of creativity in AI comes from reinforcement learning.” — Ilya Sutskever
Reinforcement learning operates on a trial-and-error basis to maximize future rewards, often surpassing the performance of models trained purely on historical data. In contrast, supervised learning minimizes loss by approximating past data, inherently constrained by the quality of that data. Synthetic data generation is closely linked with RL, where the model not only generates data through trial but also learns from the resulting rewards. This process, which involves ranking or filtering synthetic data, is functionally analogous to employing a basic RL process with a 0-1 advantage function13.
Footnotes
-
Guo, Daya, et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv preprint arXiv:2501.12948 (2025). ↩
-
Schulman, John, et al. “Proximal policy optimization algorithms.” arXiv preprint arXiv:1707.06347 (2017). ↩
-
Shao, Zhihong, et al. “Deepseekmath: Pushing the limits of mathematical reasoning in open language models.” arXiv preprint arXiv:2402.03300 (2024). ↩
-
https://lilianweng.github.io/posts/2024-11-28-reward-hacking/ ↩
-
Zhao, Yiran, et al. “How do Large Language Models Handle Multilingualism?.” arXiv preprint arXiv:2402.18815 (2024). ↩
-
Lee, Kuang-Huei, et al. “Evolving Deeper LLM Thinking.” arXiv preprint arXiv:2501.09891 (2025). ↩
-
Deng, Yuntian, et al. “Implicit chain of thought reasoning via knowledge distillation.” arXiv preprint arXiv:2311.01460(2023). ↩